
Hva er Apache Camel?
Kort oppsummert er Apache Camel et bibliotek som gjør det enkelt å implementere såkalte Enterprise Integration Patterns (EIP-er) for å integrere mellom en mengde ulike systemer og teknologier. Denne bloggposten vil ikke gå i detalj på hva Apache Camel er, se i stedet “Lurer du på hva Apache Camel er? Her får du en innføring!” skrevet av min kollega Morten Juul Torke.
Et lite utvalg av eksempler på hva slags utfordringer Camel kan hjelpe oss med er: Overføre meldinger fra Kafka til REST-tjenester eller omvendt, transformere meldingsformater mellom ulike SOAP web services, videresende filer fra FTP/SFTP til andre maskiner eller tjenester, tilby en REST-tjeneste som lagrer mottatte data ned i en database. Alt dette er selvfølgelig mulig å implementere med tradisjonell Java-kode, men med Camel får du mye funksjonalitet gratis, og det blir lettere å følge et standard mønster. Når du først har lært litt om Camel, blir det enkelt å integrere mot nye teknologier og koble det sammen med hva du allerede har.
Apache Camel er i bunn og grunn et Java-bibliotek, og kan bygges inn i kjørende applikasjoner på mange forskjellige måter. Det kan inkluderes i en helt skreddersydd Java-applikasjon fra bunnen av, eller det som kanskje er mer vanlig i dag; å kombinere det med Spring Boot. Spring Boot gjør det raskt og å komme i gang med en fungerende applikasjon med minimalt med kode og noe enkel konfigurasjon. Mange kjenner kanskje også Camel som en del av JBoss Fuse, nå Red Hat Fuse, som tilbyr en applikasjonsserver og et rammeverk som Camel-applikasjoner kan deployes til.
Mikrotjeneste-arkitektur
De senere årene har det blitt stadig vanligere med mikrotjeneste-arkitektur. Kort oppsummert innebærer det en arkitektur hvor systemene våre brytes ned i mange små, uavhengige deler som er løst koblet til hverandre. De kan gjøre utviklingssyklusen mye kortere fra ide til kjørende løsning, ved at det rulles ut små endringer på en isolert del av systemet hver gang, som også krever mindre testing og utgjør en lavere risiko for systemet som helhet.
En mikrotjeneste-arkitektur har store konsekvenser for design av kjøretidsmiljøet. I stedet for få store applikasjoner, hvor du kanskje kan dedikere en hel server eller en hel virtuell maskin til en applikasjon, så har du nå en stor samling av mange små applikasjoner som oppdateres mye oftere. Å holde styr på alle disse applikasjonene for hånd for en driftsorganisasjon blir fort en veldig krevende oppgave.
En teknologi som har grodd frem sammen med mikrotjenester er container-teknologi. Containere tilbyr en lettvekt-metode for å isolere kjørende applikasjoner fra hverandre. Den første virkelig populære container-teknologien var Docker, men de senere årene er det Kubernetes, og dens mange implementasjon som har overtatt som den mest populære kjøretidsplattformen for mikrotjenester. Der hvor Docker har mest fokus på å kjøre containere på bestemte maskiner, tilbyr Kubernetes en såkalt Platform as a Service (PaaS), hvor det tilbys en mye høyere grad av automatisering og selvbetjening for kryss-funksjonelle team. Nå kan utviklingsteamene selv rulle ut og kontrollere applikasjonene sine mens de kjører, uten å måtte gis utvidede rettigheter inn i infrastrukturen. Dette passer godt sammen med DevOps-tankegangen hvor skillet mellom utvikling og drift viskes ut.
Hvordan passer Apache Camel inn i en mikrotjeneste-arkitektur
Rent konseptuelt passer Apache Camel ytterlig inn i en mikrotjeneste-arkitektur. Det er enkelt å implementere små uavhengige tjenester med Camel som enten tilbyr funksjonalitet selv eller fungerer som “lim” mellom de andre mikrotjenestene og omverdenen.
Utfordringen som treffer applikasjoner basert på Camel, som mange andre Java-applikasjoner, er merkostnaden ved å starte opp nye instanser av Java Virtual Machine (JVM) for hver mikrotjeneste. Spesielt for applikasjoner som trekker inn mange andre større bibliotek, som for eksempel Spring Boot, kreves det mye minne (i størrelsesorden fra noen hundre MB og oppover), og applikasjonene har en betydelig oppstartstid på 15-30 sekunder eller mer. Dette høres kanskje ikke så ille ut med dagens moderne maskinvare, men se for deg at løsningen består av et titalls, eller kanskje til og med hundretalls eller tusentalls containere, og at disse skal eksistere i mange eksemplarer som en del av testmiljøer. Summen av ressursbruken blir fort høy.
Kubernetes fordeler automatisk containerne utover de tilgjengelige maskinene, og har funksjonalitet for å begrense hva hver enkelt applikasjon får lov å legge beslag på, men til syvende og sist består plattformen av avgrenset fysisk maskinvare. Dersom du deler Kubernetes-clusteret med andre, slik som er vanlig med skytjenester, er det også ressursbruken per applikasjon som faktureres og representerer en direkte kostnad.
Oppstartstid i Kubernetes er også viktig å holde på et så lavt nivå som mulig. Dette påvirker blant annet hvor raskt nye versjoner av mikrotjenestene kan rulles ut, og hvor raskt de kan skaleres ut med flere instanser (horisontal skalering). Applikasjonene må også tåle å bli restartet når som helst av Kubernetes av ulike grunner, for eksempel grunnet vedlikehold av serverne eller clusteret. I verste fall kan det føre til nedetid for brukerne dersom applikasjonene ikke starter opp raskt etter en restart.
Disse utfordringene følger av arven Java har med fra tidligere før mikrotjenester ble populært. Da hadde applikasjonene tilgang på ressursene til hele maskinen de kjørte på, og høy ytelse over tid var viktigere enn rask oppstartstid. Det gjøres utstrakt optimalisering av applikasjonen mens den kjører etter oppstart, slik at ytelsen blir best mulig etter en stund. Minnehåndteringen preges også av å ikke være optimalisert for mange små mikrotjenester, men heller større applikasjoner, selv om det har kommet en del forbedringer rettet mot containere de siste årene.
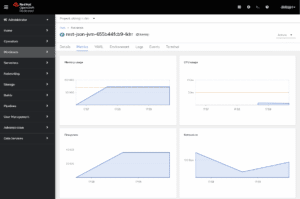
Eksempelapplikasjon for Camel Quarkus (https://github.com/apache/camel-quarkus-examples/tree/main/rest-json) kjørende i en JVM som en pod i OpenShift/Kubernetes. Selv om Camel Quarkus er et meget lettvekt Java-rammeverk i seg selv ligger minnebruken på over 70MB med en slik ”hello world” applikasjon som eksponerer et enkelt REST API. Dersom tilsvarende applikasjon var basert på Spring Boot ville minnebruken vært enda høyere.
Quarkus
Quarkus er et open source rammeverk for Java som er laget spesielt med tanke på å lage så ressurseffektive applikasjoner som mulig, med en mulighet for å bygge applikasjonen som et såkalt “native image” vha. GraalVM. Et native image er en utgave av en applikasjon som er skrevet i Java, men i stedet for å kompileres til bytekode som blir kjørt i en JVM, kompileres applikasjonen direkte til maskinkode spesifikk for plattformen den skal kjøre på. Fordelen med et native image er i hovedsak oppstartstid og minnebruk. Der hvor en JVM bruker mye tid når den starter opp på å kompilere og optimalisere koden, er dette allerede gjort på forhånd i et native image. I tillegg lastes kun den funksjonaliteten som faktisk benyttes i applikasjonen, og ikke hele JAR-filer for eksterne biblioteker. Resultatet av dette er en nærmest umiddelbar oppstartstid, og i mange tilfeller en størrelsesorden lavere minnebruk, hvor applikasjonen bruker noen titalls MB i stedet for hundretalls MB etter oppstart.
Du mister noen av fordelene med Java ved bruk av et native image siden den kompilerte applikasjonen ikke er portabel til andre plattformer, og en del optimalisering og støtteverktøy mens applikasjonen kjører. Men i et scenario hvor alle applikasjonene kjøres i Kubernetes er dette ofte et lite offer sammenlignet med fordelene man oppnår.
Camel Quarkus
Camel Quarkus er et rammeverk som har bygget det aller meste av Apache Camel til å fungere sammen med Quarkus, og som kan bygges til et native image. Det består av et sett med avhengigheter som kan importeres med Maven eller Gradle byggverktøyet som erstatter de vanlige Apache Camel-avhengighetene. Kodemessig benyttes de samme klassene som du ellers gjør med Apache Camel, men noen av “plattformtjenestene” er naturligvis annerledes enn med andre implementasjoner som for eksempel Spring Boot. Dette gjelder blant annet tjenester som autentisering og observerbarhet/metrikker.
Camel Quarkus inkluderer en utviklingsserver du kan kjøre på lokal maskin som starter applikasjonen i en tradisjonell JVM, og laster automatisk nye versjoner av koden etter hvert som den endres. Applikasjonen kan også bygges som en kjørbar JAR-fil til slutt som kan kjøres i en JVM akkurat som vanlig, og deployes til Kubernetes eller servere på den måten.
Men for å virkelig dra nytte av Camel Quarkus må applikasjonen bygges som et native image, som krever at det installeres litt flere verktøy. Det første som er nødvendig er en versjon av en GraalVM-basert JDK. Quarkus anbefaler at du benytter Mandrel som er en fork av GraalVM uten lisenskostnader knyttet til seg, men det er også mulig å bruke GraalVM fra Oracle. I tillegg til Mandrel, så må det installeres en C-kompilator og tilhørende verktøy på maskinen. For Linux består dette normalt av noen pakker som må installeres; på Mac benyttes XCode og på Windows kreves Visual C++ Build Tools. I de fleste tilfeller er det 64-bit Linux som er operativsystemet for maskinene som kjører Kubernetes hvor applikasjonen skal deployes, og er mest relevant. Eventuelt kan du la byggeserveren (f.eks. GitHub Actions, GitLab CI, Jenkins etc.) ta seg av bygget av native image og jobbe med JVM på lokal maskin.
Når det er bygget et native image så ender du opp med en monolittisk kjørbar fil hvor alt som trengs for å kjøre applikasjonen er inkludert, som erstatning for en stor JAR-fil. Bygges det en container som inkluderer applikasjonen trengs det kun et helt minimalt image, hvor det ellers for en Java-applikasjon må inkluderes en JRE/JDK.
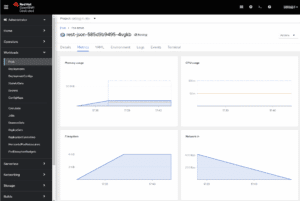
Samme eksempelapplikasjon som tidligere for Camel Quarkus, men kompilert til et native image. Minnebruken er nå nede i under 14MB.
Utfordringer med Camel Quarkus
Er det så bare fordeler med Camel Quarkus? Som alt annet er det både fordeler og ulemper med å bruke Camel Quarkus versus en tradisjonell Java-implementasjon.
Den kanskje største ulempen er begrensninger på hvilke andre tredjeparts-biblioteker du kan nyttiggjøre deg av i en Camel Quarkus applikasjon. Det er mange større Java-biblioteker i dag som ikke takler å bli kompilert til native image. Forenklet så kan man si at disse bibliotekene bruker diverse “triks” som baserer seg på at de kjører i en JVM for å fungere. For å kunne kompileres til et native image så må de eksplisitt implementere støtte for det, for å erstatte “triksene” de normalt baserer seg på. Dette er for eksempel grunnen til at du ikke til nå uten videre har kunnet kompilere Spring-applikasjoner til et native image, men måtte basere deg på eget prosjekt ved navn Spring Native (Spring Boot 3.0 overtar nå for Spring Native). Når mikrotjenestene designes bør dette holdes i bakhodet, slik at applikasjonene deles opp på en måte som ikke gjør det tvingende nødvendig å trekke inn avhengigheter som ikke er kompatible. Du har også muligheten å kjøre Camel Quarkus applikasjoner i en JVM i en overgangsperiode.
Byggetiden for et native image er vesentlig høyere enn for tilsvarende tradisjonelle Java-applikasjoner. Dette kommer bla. av at optimaliseringen som vanligvis gjøres under oppstart av en JVM må gjøres under kompilering i stedet. Verktøykjeden er også lenger, det holder ikke lenger å laste ned en Java JDK, du må ha verktøy for å kompilere C-kode i tillegg, og en spesialisert GraalVM/Mandrel JDK.
En ulempe for feilsøking i produksjon er også at applikasjonen som kjører på utviklers maskin (JVM) ikke er den samme som kjører i produksjon (native image). Det kan føre til nye feil som ikke opptrer lokalt, eller at feilmeldinger blir annerledes. Dette bør tas hensyn til under testing, så ikke applikasjonen spinnes opp som native image for første gang i produksjon.
Sist, men ikke minst, må det også nevnes at Camel Quarkus er basert på en del ganske fersk teknologi, som ikke nødvendigvis har samme nivå av modenhet og support som en JVM/Camel-basert løsning. Dette må organisasjonen vurdere risikoen av selv, og det avhenger naturligvis av bruksområdet til applikasjonene der Camel Quarkus benyttes.
Oppsummering
Camel Quarkus er et spennende nytt rammeverk som lar oss bygge applikasjoner basert på Apache Camel som er optimalisert til å fungere mye smidigere i en mikrotjeneste-arkitektur enn en tradisjonell JVM-basert applikasjon. Det gjør det mulig å bygge løsningen med mange separate mikrotjenester uten å bekymre seg over høy ressursbruk og tilhørende kostnader som følger med JVM-er. Java-applikasjoner kompilert til maskinkode er fortsatt et relativt nytt fenomen og et område hvor det foregår rask utvikling, men hvis det tas hensyn til begrensningene fra begynnelsen av prosjektet kan det ha store fordeler når løsningen skal rulles ut.
Hvis du er nysgjerrig og ønsker å komme raskt i gang med Camel Quarkus så er deres “First steps” guide et godt utgangspunkt.